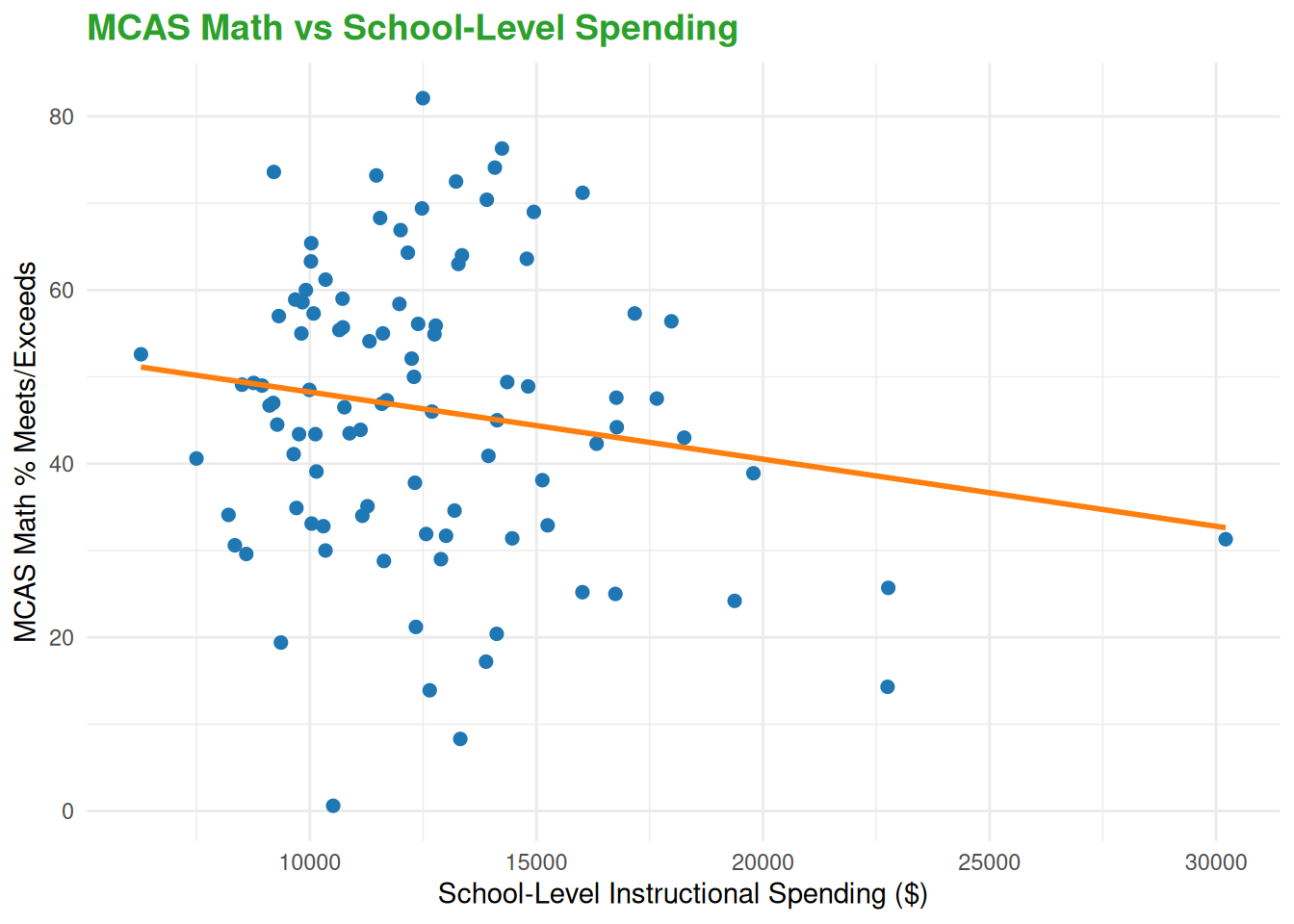
Each dollar spent in school-level instructional spending is associated with a 0.00115 percentage decease in the percentage of students in grades 3 to 8 that met or exceeds expectations on the MCAS Math examination, holding all other spending constant.
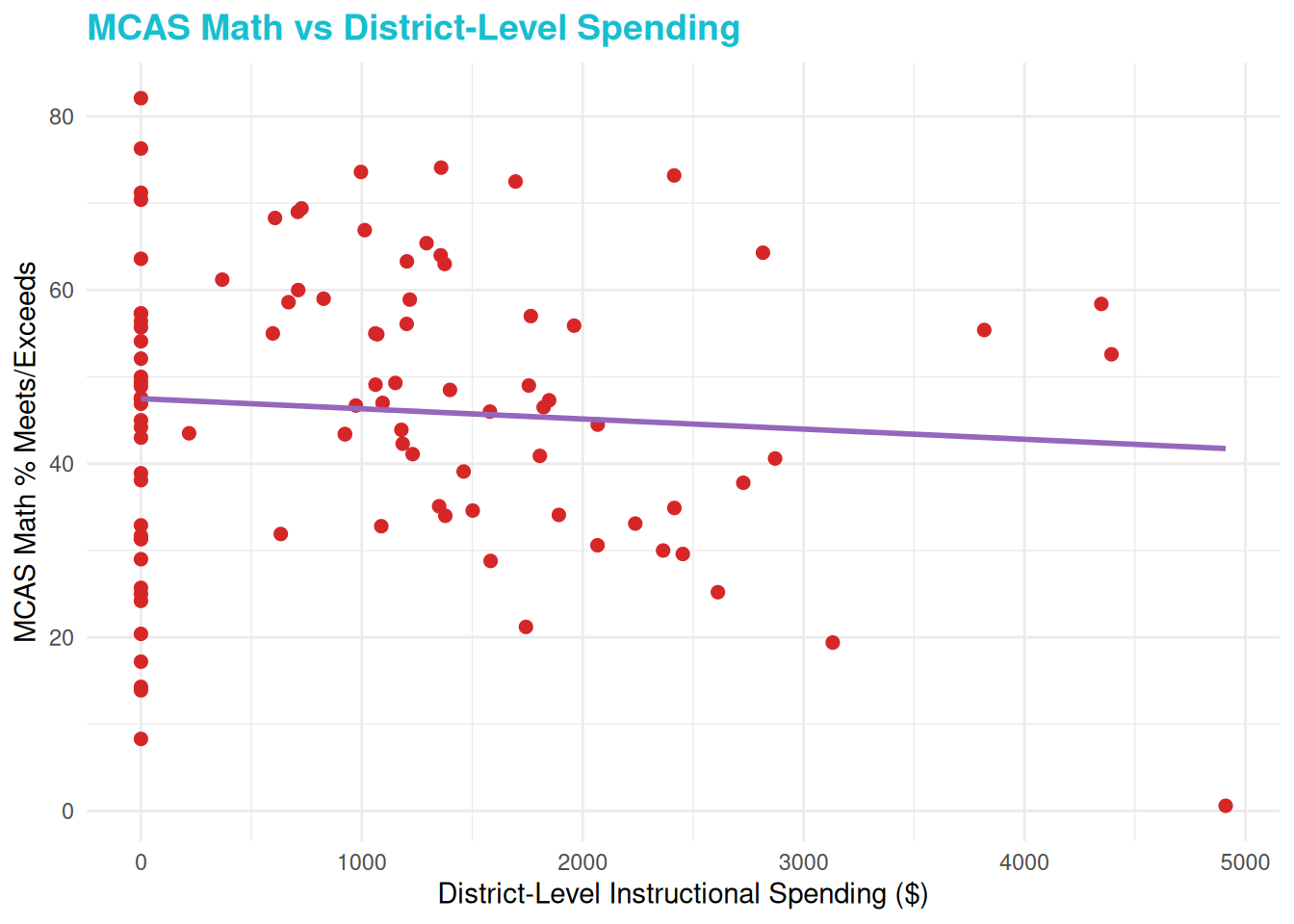
Each dollar spent in distinct level instructional expenditures is associated with a 0.00302 percentage decrease in the percentage of students in grades 3 to 8 that met or exceeds expectations on the MCAS Math examinations, holding all other spending constant.
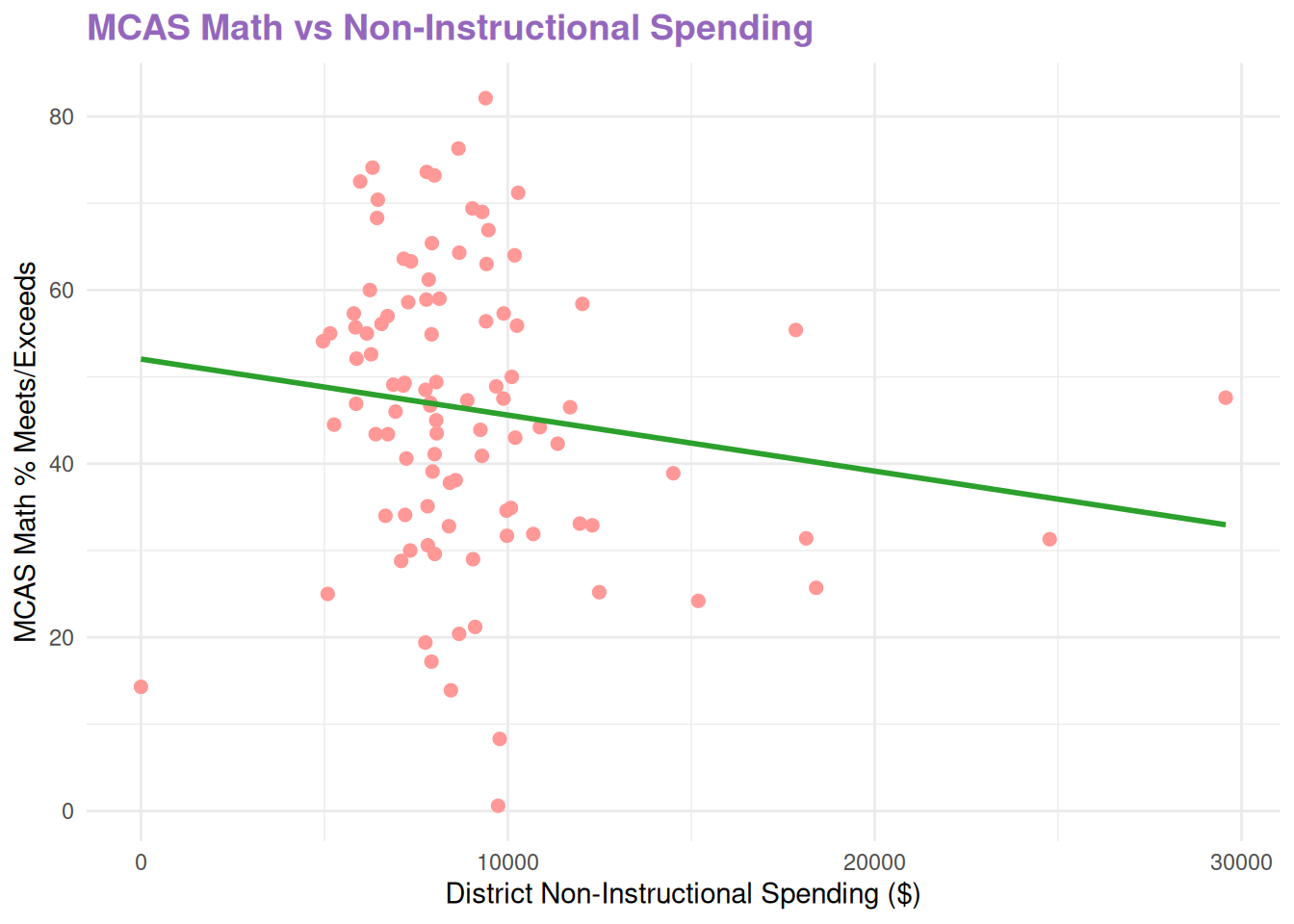
Each dollar spent in District Non-Instructional Expenditures is associated with a 0.0002 percentage decrease in the percentage of students in grades 3 to 8 that met or excceded expectations on the MCAS Math examinations, holding all other spending constant.
Questions of weither or not the pass rate is impacted by retakes (thus making it lower)
Plot:
Code
library(ggplot2)# Scatterplot: School-Level Instructional Spendingggplot(analysis_df, aes(x =`School-Reported Instructional Expenditures`,y =`Math Grades 3-8 % Meets or Exceeds`)) +geom_point(color ="#1f77b4", size =2) +# blue pointsgeom_smooth(method ="lm", se =FALSE, color ="#ff7f0e") +# orange linelabs(x ="School-Level Instructional Spending ($)",y ="MCAS Math % Meets/Exceeds",title ="MCAS Math vs School-Level Spending" ) +theme_minimal() +theme(plot.title =element_text(color ="#2ca02c", size =14, face ="bold"))
Code
# Scatterplot: District-Level Instructional Spendingggplot(analysis_df, aes(x =`District-Level Instructional Expenditures`,y =`Math Grades 3-8 % Meets or Exceeds`)) +geom_point(color ="#d62728", size =2) +# red pointsgeom_smooth(method ="lm", se =FALSE, color ="#9467bd") +# purple linelabs(x ="District-Level Instructional Spending ($)",y ="MCAS Math % Meets/Exceeds",title ="MCAS Math vs District-Level Spending" ) +theme_minimal() +theme(plot.title =element_text(color ="#17becf", size =14, face ="bold"))
Code
# Scatterplot: District Non-Instructional Spendingggplot(analysis_df, aes(x =`District Non-Instructional Expenditures`,y =`Math Grades 3-8 % Meets or Exceeds`)) +geom_point(color ="#ff9896", size =2) +# pink pointsgeom_smooth(method ="lm", se =FALSE, color ="#2ca02c") +# green linelabs(x ="District Non-Instructional Spending ($)",y ="MCAS Math % Meets/Exceeds",title ="MCAS Math vs Non-Instructional Spending" ) +theme_minimal() +theme(plot.title =element_text(color ="#9467bd", size =14, face ="bold"))